
Appearance
GPT-SoVITS
GPT-SoVITS是开源社区的低成本AI音色克隆软件。更多资料信息请查阅GSV语雀官方文档和官方项目,官方文档是GSV本体程序(训练+推理)的指南,和本文后续所使用的官方语音合成整合包(仅推理)的使用略有差异。
接入话树流程:
话树提供免费接入官方提供的语音合成整合包的推理配音,您可以在话树使用更易上手的单人配音与多人配音功能。Windows用户在本地使用的具体操作步骤如下(其他系统用户请自行查阅官方资料下载对应程序并结合下述操作步骤进行接入):
📎 本指南基于AI-Hobbyist资源网盘中2025-03-22发布的整合包版本。不同版本的整合包的运行方法或内部文件可能略有差异,以实际情况为准。
1. 下载整合包
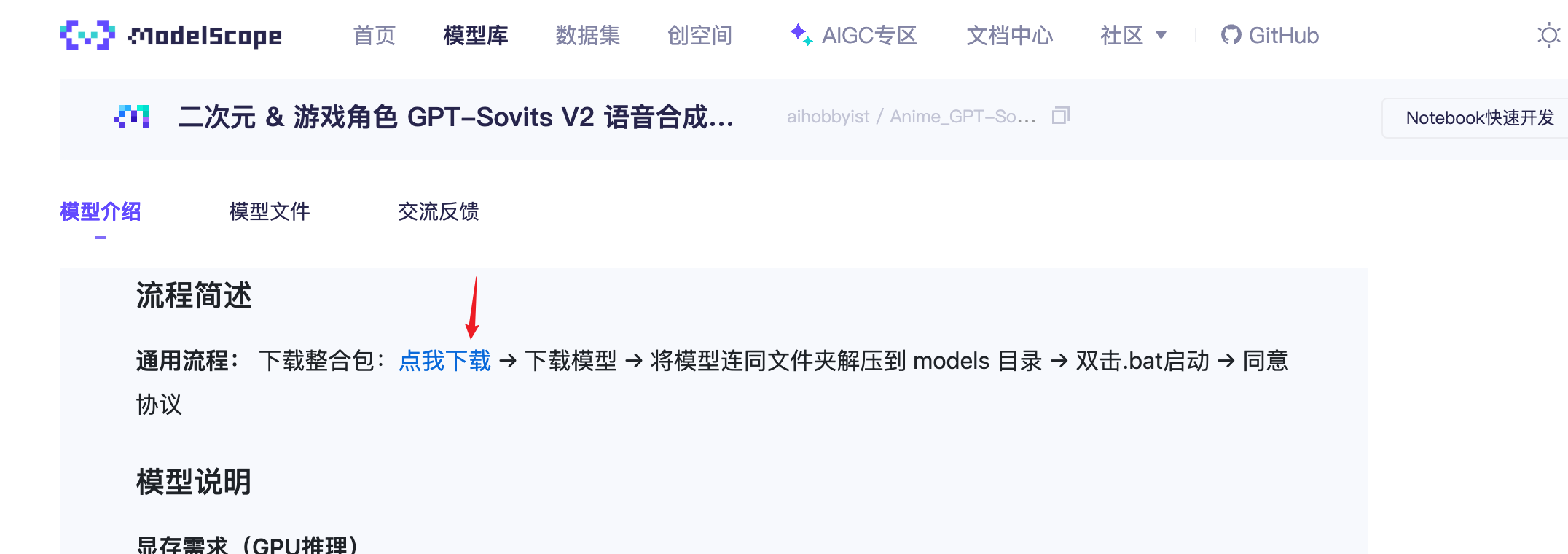
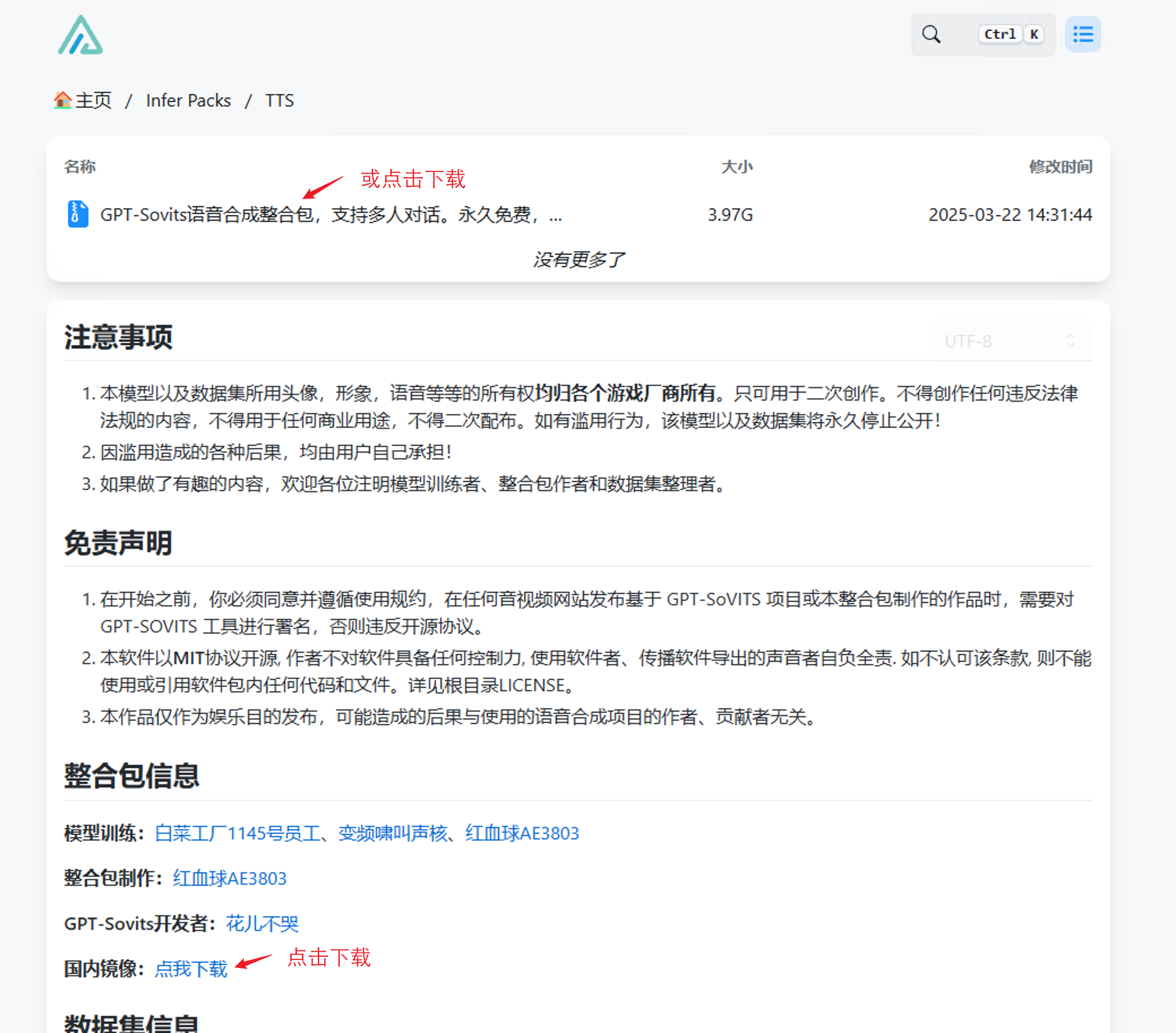
进入官方分发网站,Anime_GPT-Sovits_Models,阅读声明事项后,找到“流程简述”段落中的“点我下载”进入二级网页,找到“整合包信息”中的国内镜像的“点我下载”。
2. 启动GSV整合版程序
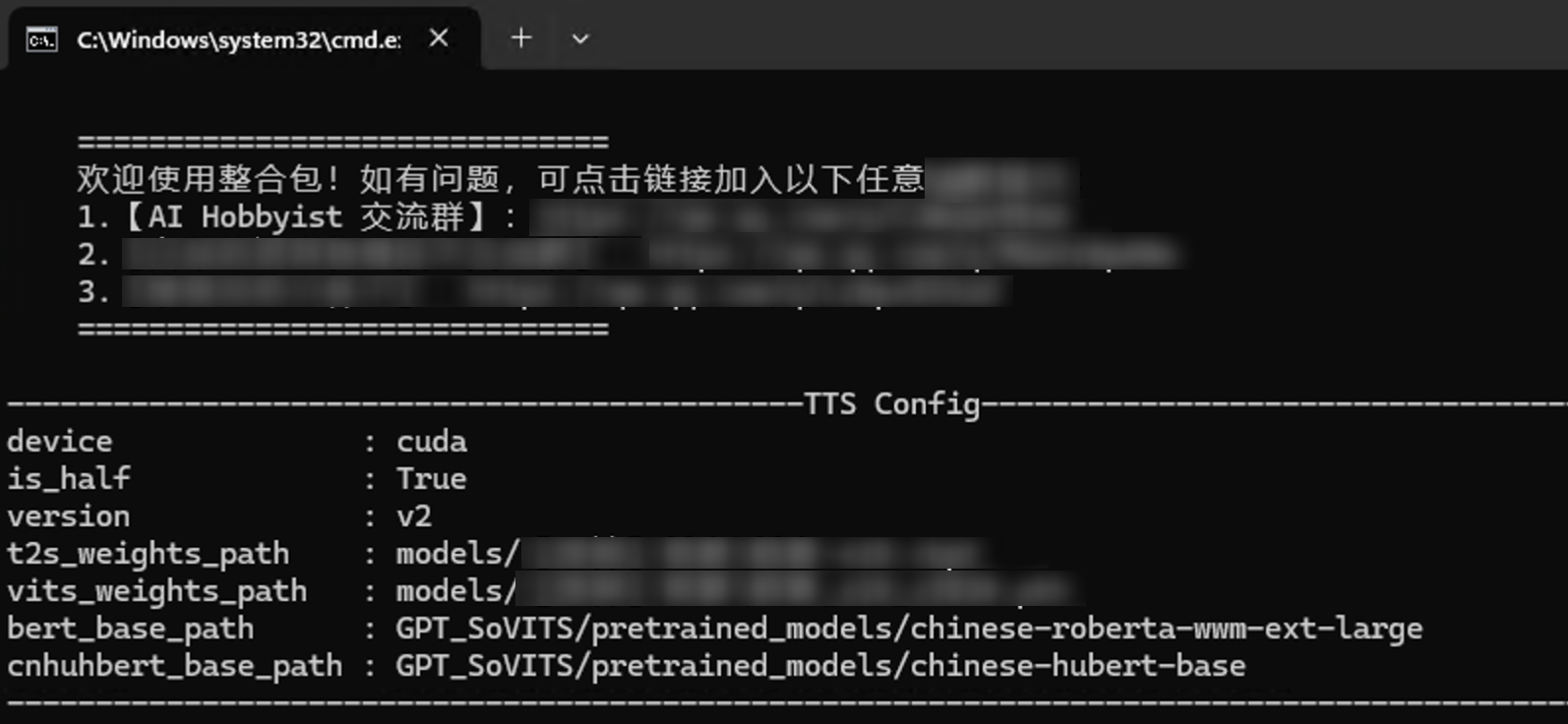
下载并解压后(一定要先解压),找到程序目录中的【语音合成.bat】运行,若您的电脑显卡为Nvidia独立显卡则优先选择CUDA启动。若出现Windows安全中心或其他弹窗发现风险项等,请自行决定是否同意此开源程序运行以继续后续流程。

片刻时间后会出现终端控制台,请不要关闭它。若您为第一次启动,可能需要根据终端提示同意协议。
3. 获取API请求地址
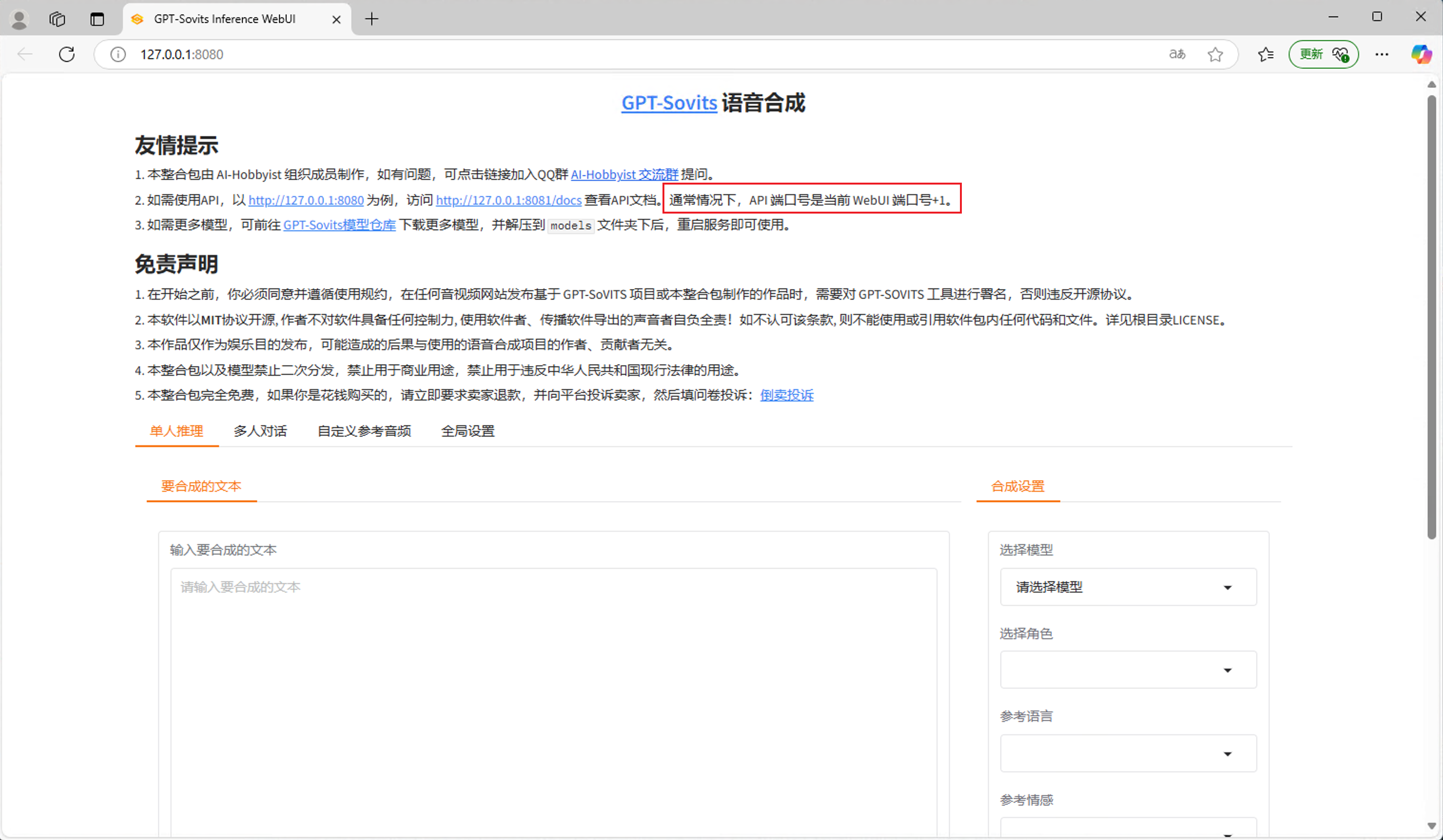
正常默认情况下,片刻时间后会自动在浏览器打开标题为“GPT-Sovits Inference WebUI”的网页。
💡 请检查网址栏是否为 http://127.0.0.1:8080 ,如果相同,则您可以跳过第3步的后续内容,在第4步的配置页面中直接点击确定。
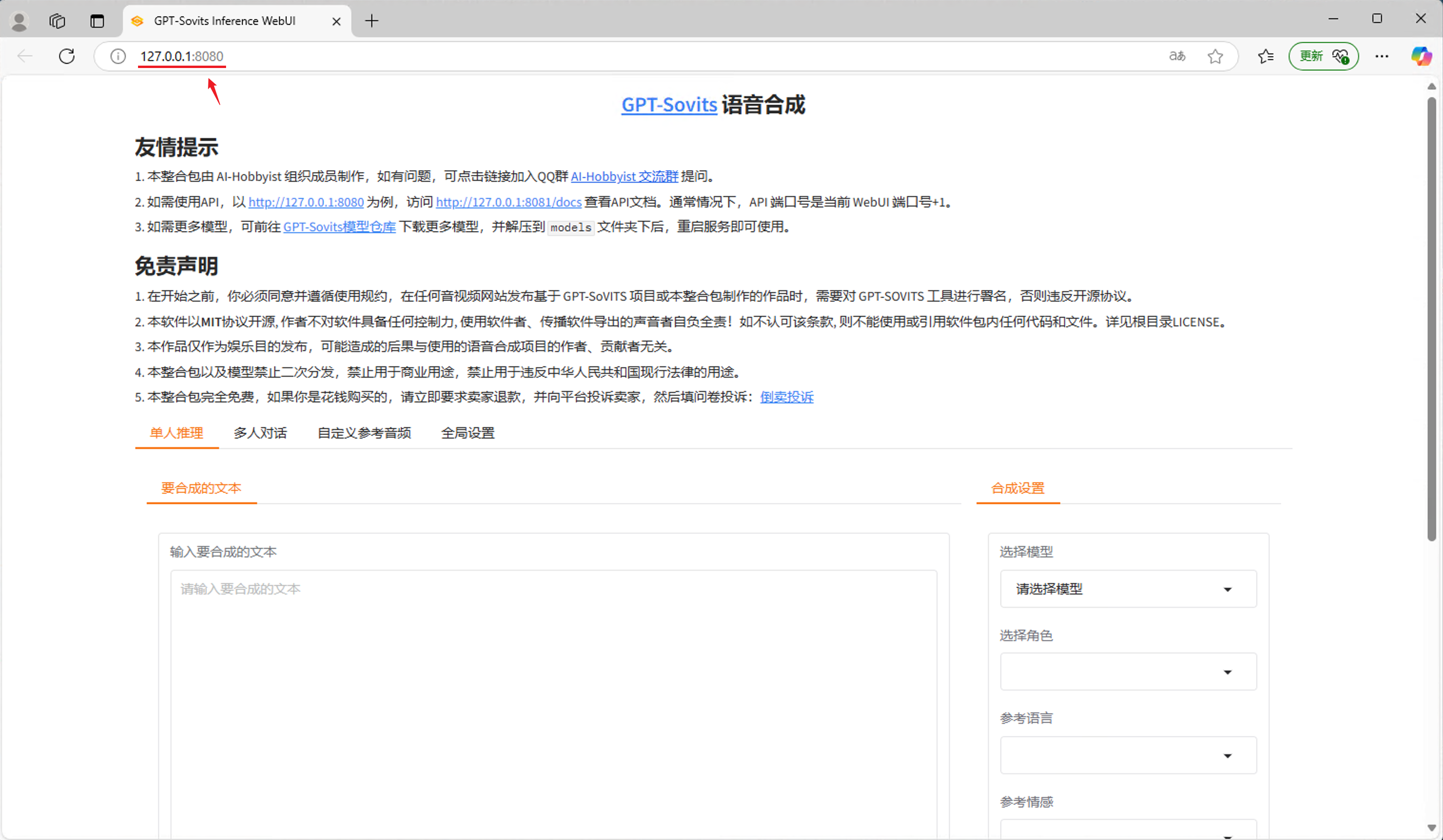
您需要找到GVS程序的API请求路径或API文档的网址路径。
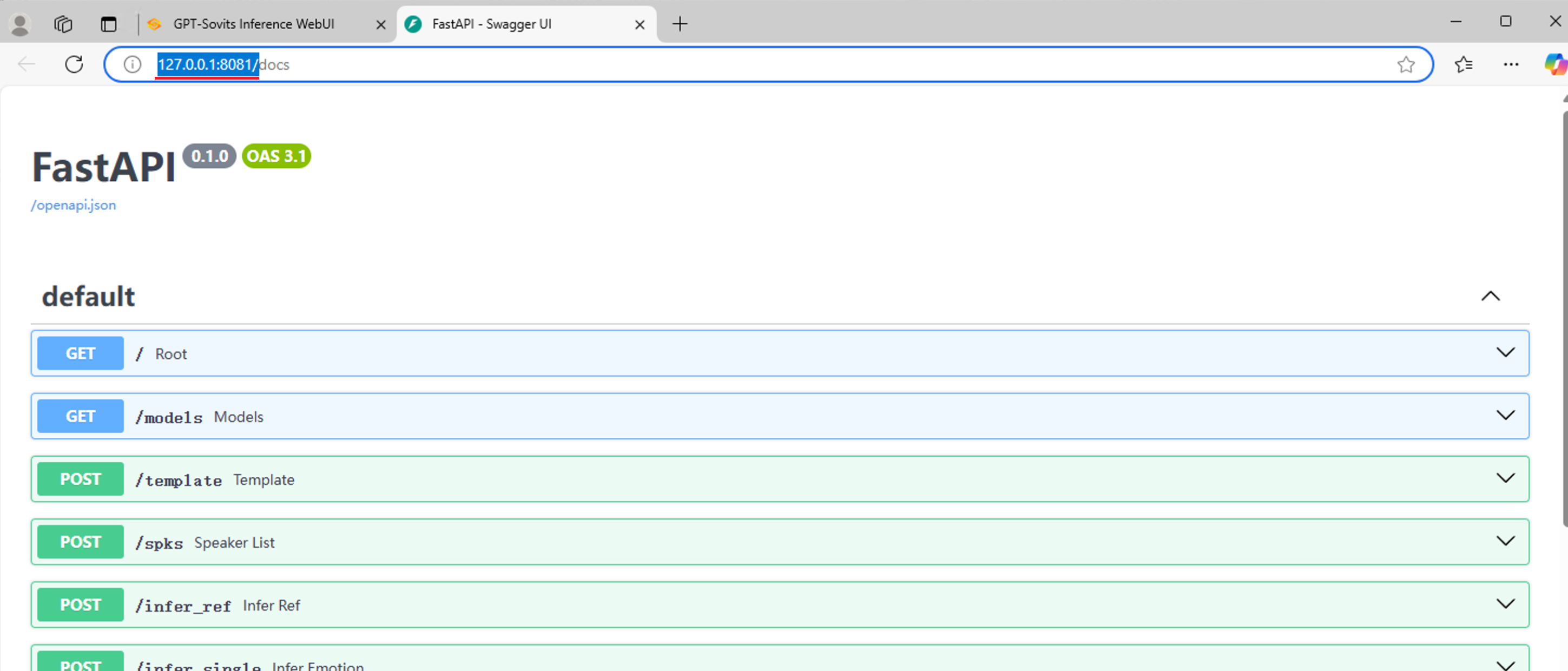
以默认通常情况举例,WebUI网页运行在本机8080端口下,API端口号是当前WebUI端口号+1,那么您的API请求地址则是 http://127.0.0.1:8081 。您可以访问 http://127.0.0.1:8081 或 http://127.0.0.1:8081/docs 来检查API服务是否正常。

4. 配置话树插件
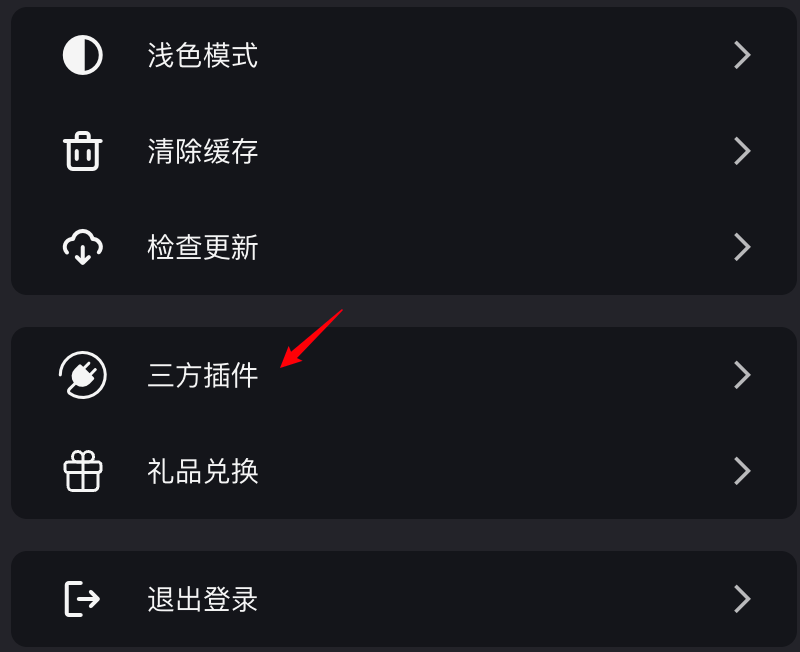
登录话树,在主页点击头像,在个人中心找到“三方插件”进入。
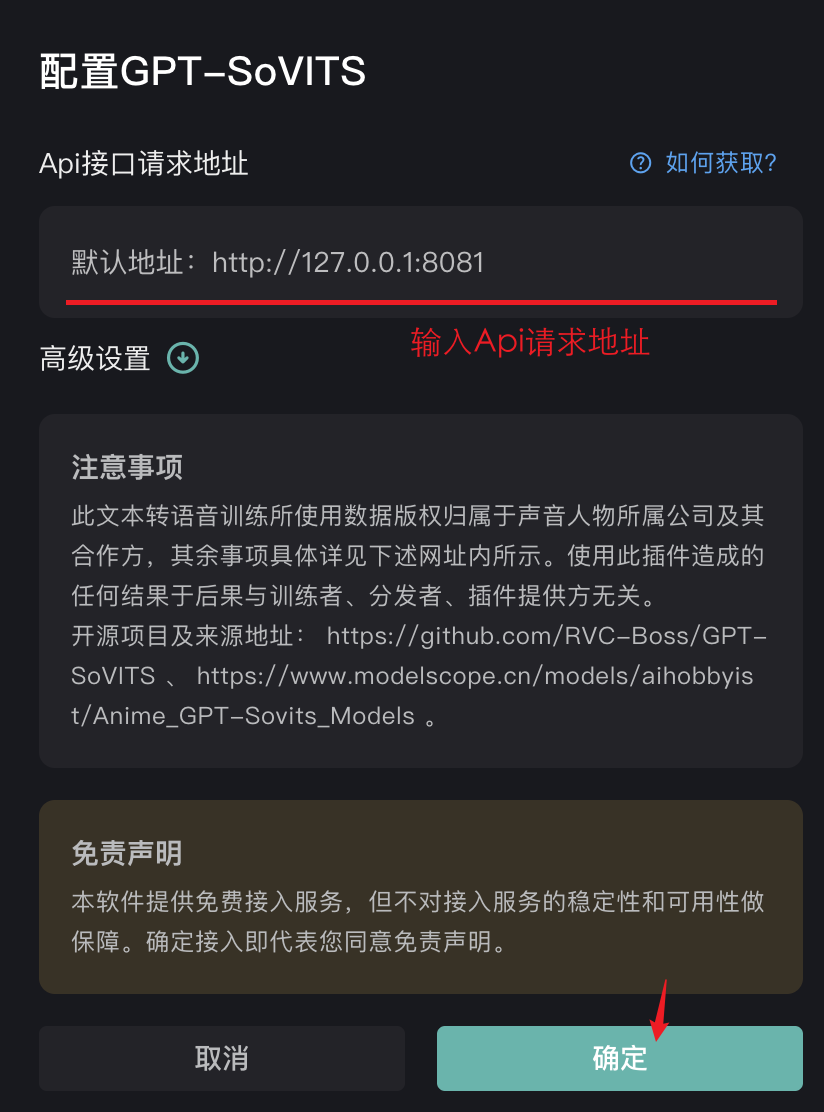
点击“GPT-SoVITS”的接入配置,输入上一步骤得到的网址(默认情况下为 http://127.0.0.1:8081 )后点击确定,在可用性检查通过后,便配置完成,此时便可以使用新的声优参数进行配音。

5. 开始使用
免责声明
话树提供免费接入服务,配音过程中若您选择此插件的配音声优,不会消耗您的话树配音条数资源;但话树不对接入服务的稳定性和可用性做保障;确定接入即代表您同意免责声明。
请尽情使用此部署在您设备上的低成本的开源配音吧!在配音过程中请不要关闭终端控制台,重启电脑后需要重新运行GSV程序(重新运行.bat文件)。
Q&A:
1. 如何使用更多的声优进行配音?
您可以下载官方社区提供的更多配音模型。
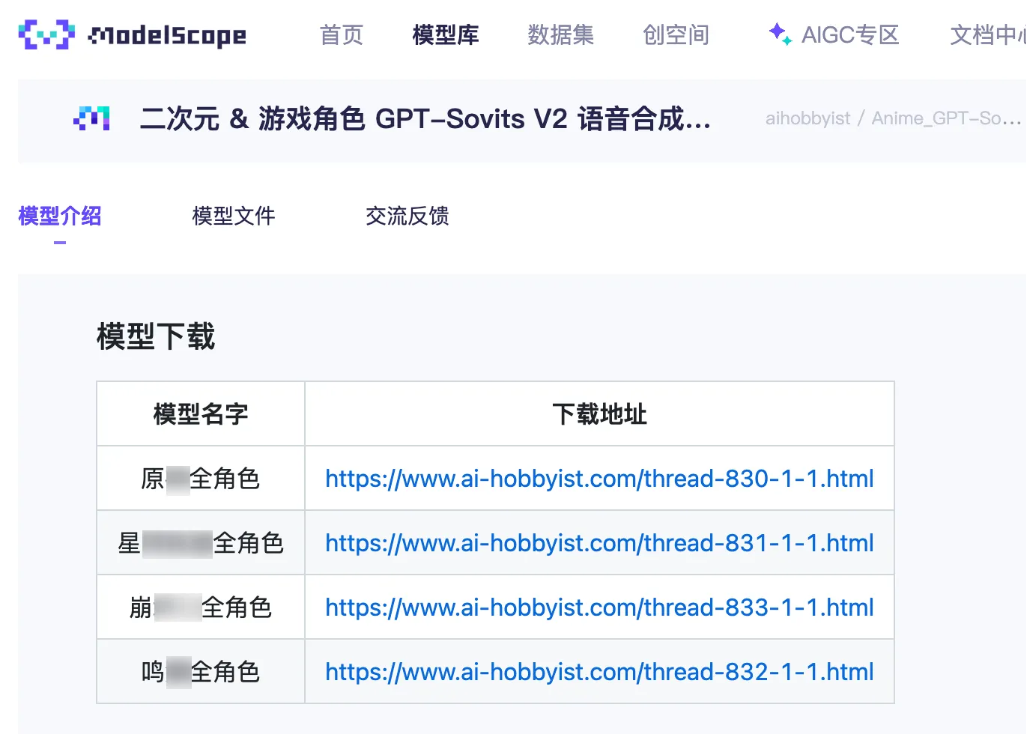
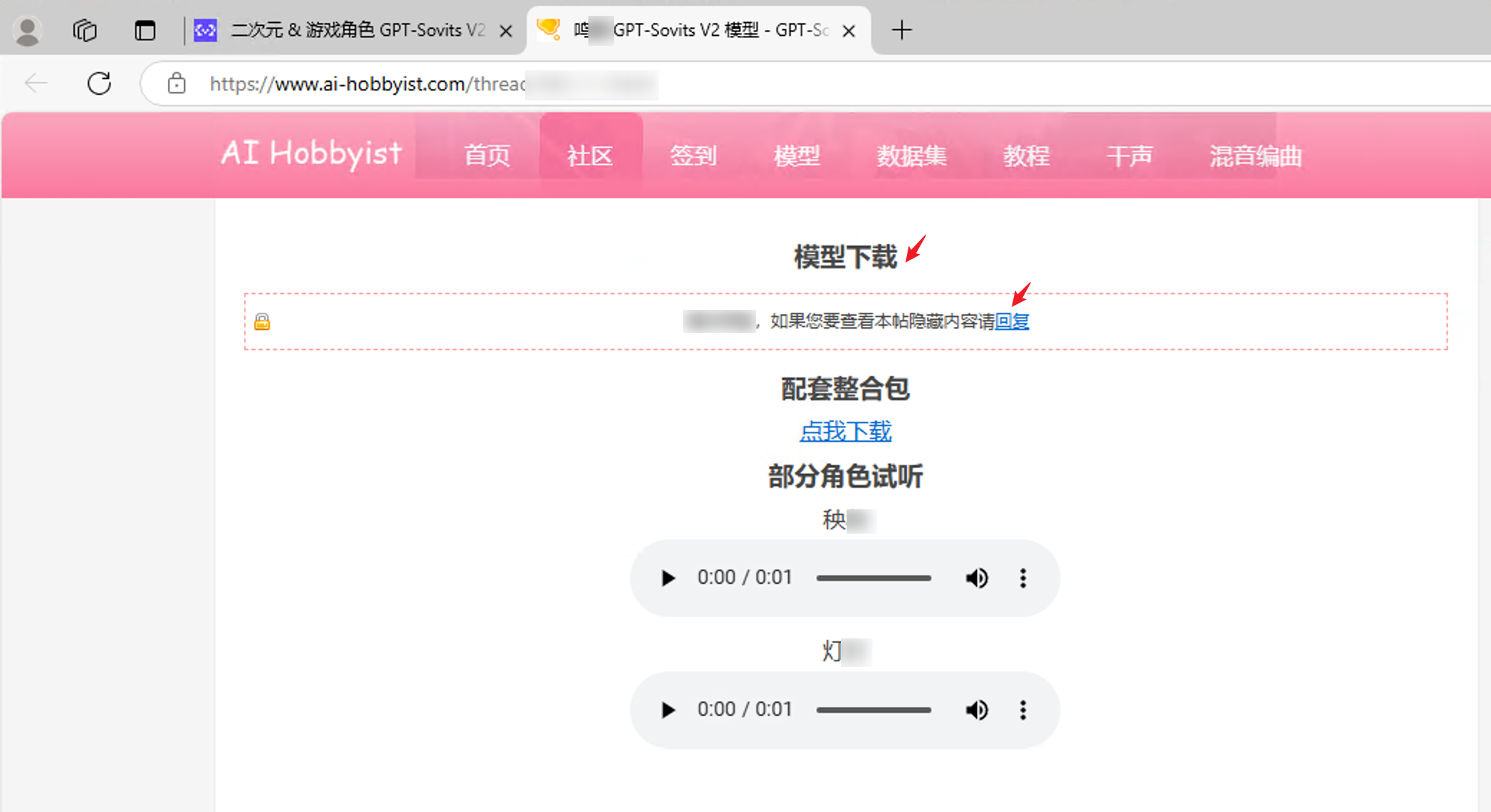
下载完成后将解压后的文件夹放置于整合包的/models文件夹下。
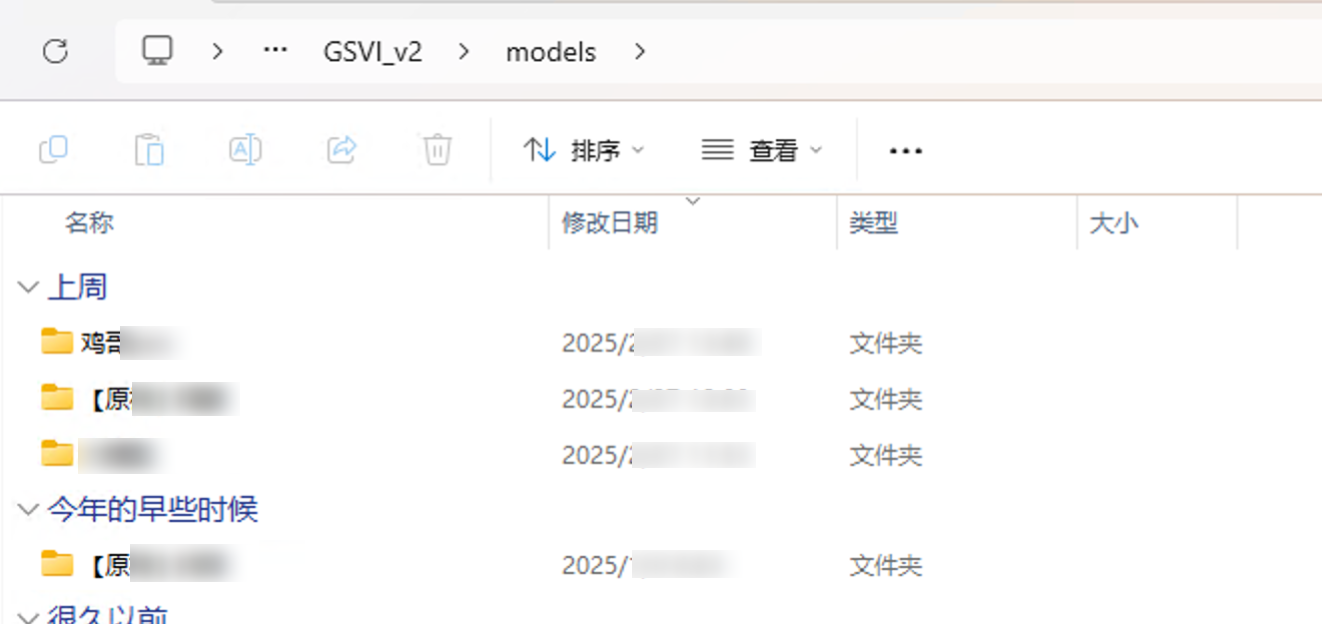
若GSV正在运行中,请先关闭程序;重启GSV程序,等待浏览器自动打开网页则代表GSV启动成功。此时若你能正在“GPT-Sovits Inference WebUI”的网页中看到新的模型与配音员且能正常配音,则表示操作成功。
之后重启话树即可自动读取新的声优列表,或者进入三方插件配置页面再次点击确定按钮以读取新的声优列表。
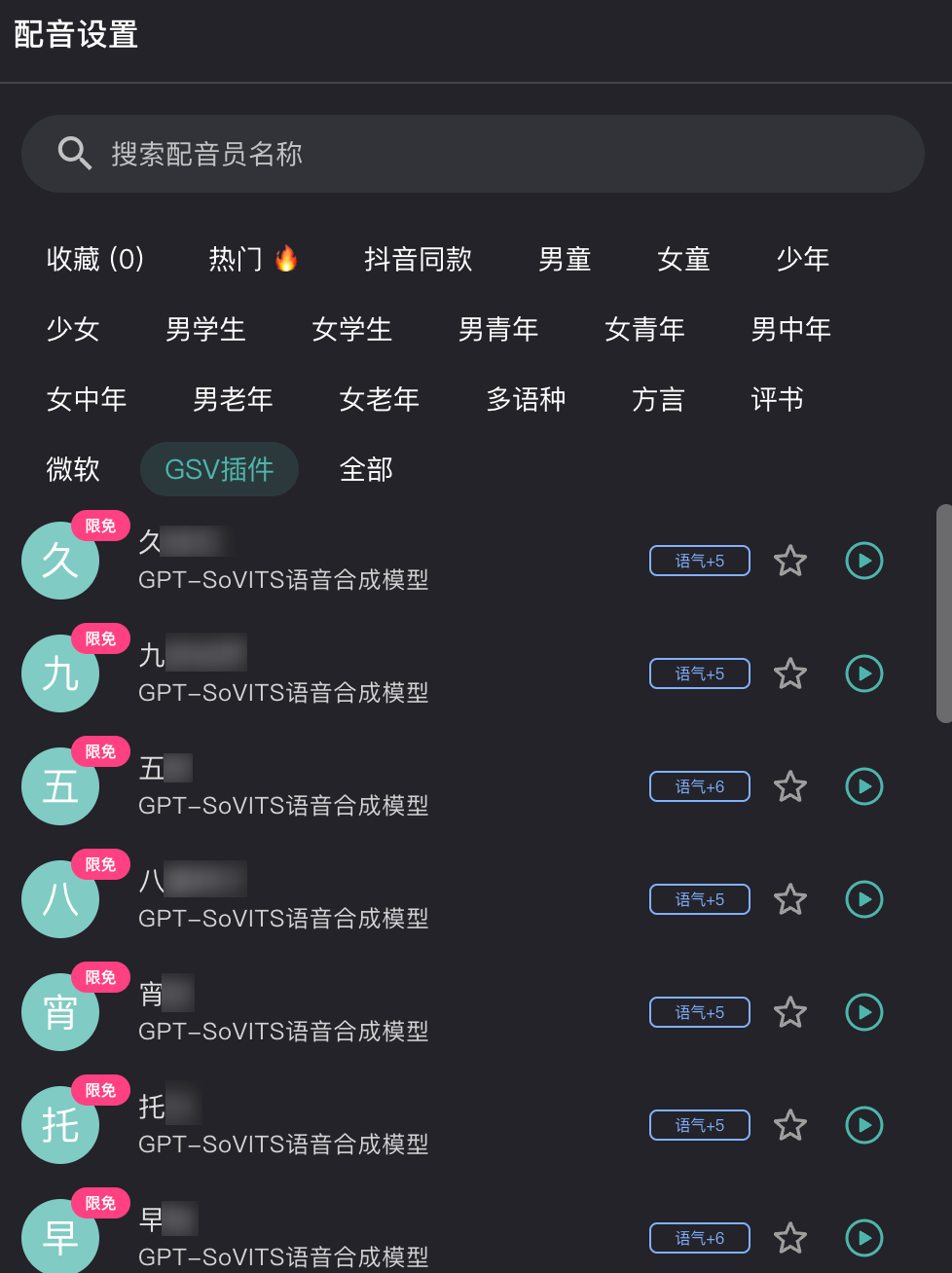
2. 如何获得更多的声优,以及想训练私有配音模型使用?
您可以前往官方社区自行下载别人提供的模型(注意:社区里某些下载后的文件并不能直接使用,您需要参考本指南的附录1配置模型与参考音频),之后同Q&A第一问后续的验证配音操作,成功后即可在话树内使用。
模型训练教程请自行查阅网络视频资料使用官方项目进行配音模型的训练,并参考本指南的附录1配置模型与参考音频,验证配音,即可使用。
模型的支持语种为:中文、英语、日语、粤语、韩语、中英混合、日英混合、粤英混合、韩英混合、多语种混合、多语种混合(粤语)。请保证语种文件夹命名为上述其一。在非中文语种的情况下,您可能会遇到运行错误等问题,此时请自行参考网络资料进行解决。
3. 如何快速克隆某个声音?
如果您不想要经过处理、分类、校对标注、自训练出极佳私有模型的话,您可以使用开发者提供的预训练模型达到快速克隆出一个声优的目的。
免责声明
快速克隆仅作为娱乐目的发布,严禁用于违反当地法律的用途,可能造成的后果与语音合成项目的开发者、分发者、接入方无关;使用合成的声音造成的不良后果由使用者自负全责。
请参考本文的附录1,配置模型与参考音频。
您可以使用整合包中/GPT_SoVITS/pretrained_models/gsv-v2final-pretrained文件夹里的这两个预训练模型文件作为模型,s2G2333k.pth和s1bert25hz-5kh-longer-epoch=12-step=369668.ckpt。
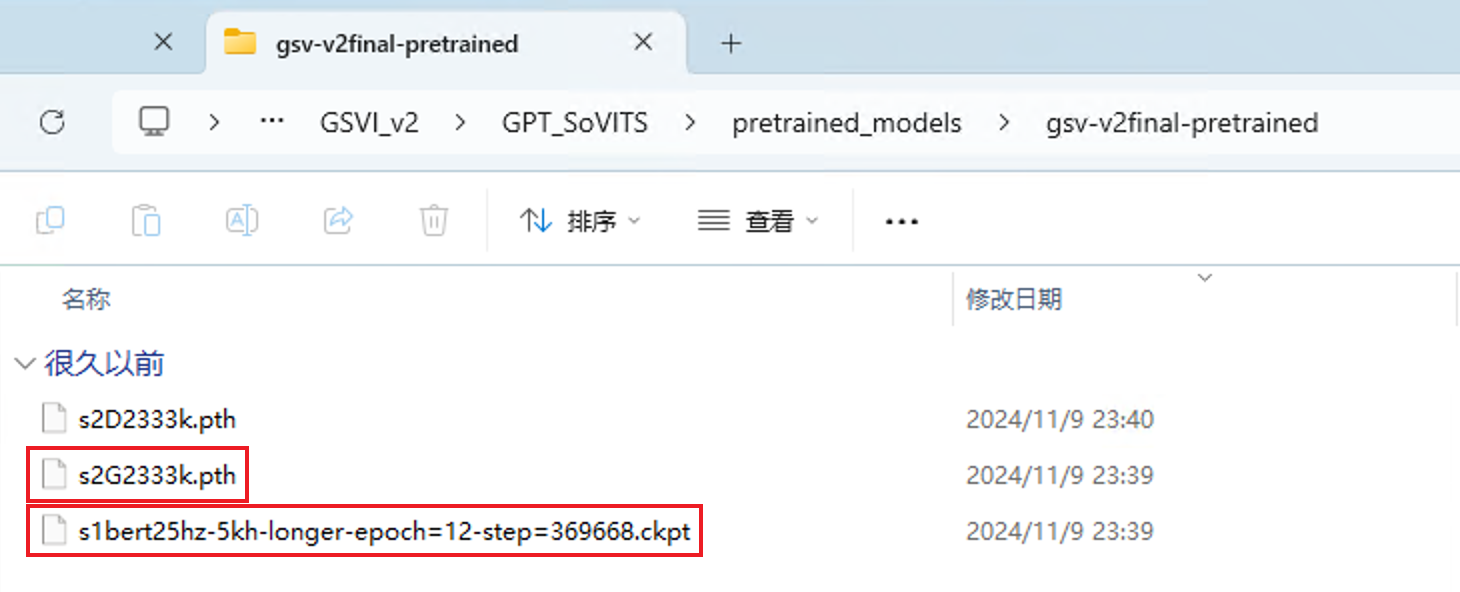
💡 快速克隆声音的效果受参考音频与模型影响。部分声色可能在此预训练模型下效果不佳,您需要自己完整训练私有语音模型或查找网络信息尝试搭配其他模型。
配置好声优名称、音频、参考文本、语气等之后,你便快速克隆出了某个声优。
通过语音合成的webUI界面验证能成功配音后,即可在话树内使用。
4. 如何在移动设备上使用?如何使用非本地部署?
首先,您必须将GSV程序运行在一台电脑/服务器上。
之后您可以结合接入话树的操作步骤等并自行查询网络资料,获得有效的Api请求地址。
您可能需要自行解决局域网部署、公网代理、CORS、修改代码等相关问题。
5. 如何更快速的启动本地Api请求服务?
如果您想要节省系统资源,不需要webUI界面,可以自行阅读整合包代码并创建.bat启动文件,您需要自行保证其Api服务的可用性。
如下的批处理文件仅供参考。
shell
REM 一键启动语音合成API(CUDA).bat
@echo off
"runtime/python.exe" api.py -d cuda -p 8081 -s 0.0.0.0
pause6. 什么是终端/控制台?什么是显卡/显存/CUDA?什么是…?
专业名词您可以自行查阅网络资料并结合官方资料进行理解。
7. 运行出现问题?我想要这样的功能…
请自行查询网络资料或询问DeepSeek等AI助手解决。
声音克隆和二次元配音使用的是相同的三方插件,但声音克隆需要自行创建文件夹,具体操作点击查看教程视频。
附录
1. 如何管理自己的模型与参考音频文件?
当您自训练了私有语音模型、或下载了他人的单独模型、亦或者想使用整合包内的预训练模型,您可能会需要将相关文件加载进程序,这样您便可以读取到新的声优信息。
您有如下两种方式可以进行管理:
方式一:可视化网页管理,更适用于少量参考音频。
找到程序目录中的【模型管理器.bat】运行

片刻时间后会出现终端控制台,请不要关闭它;并会在浏览器打开如图所示的网页。
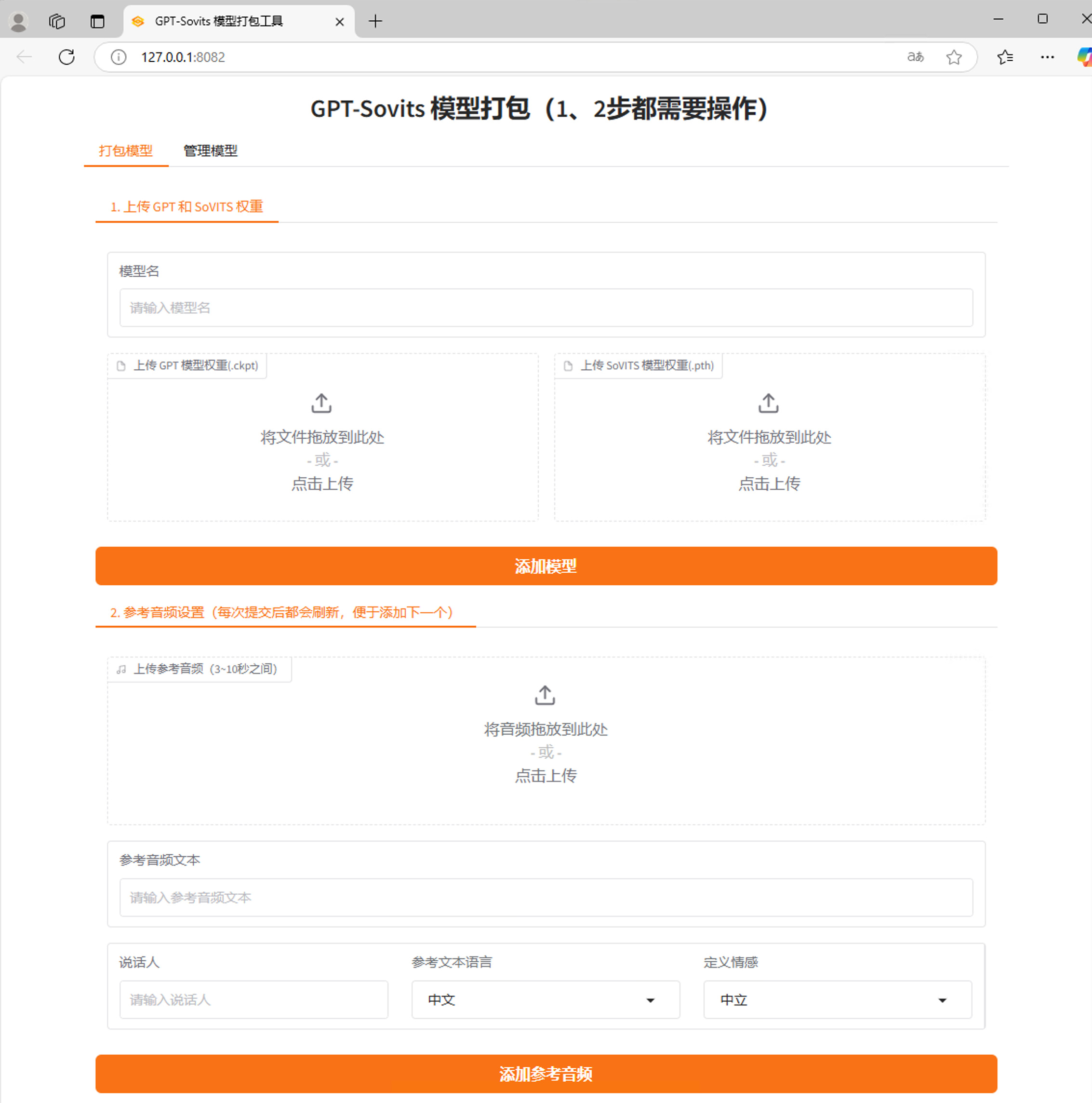
请按照网页所示流程,您即可在“打包模型”的标签页面中先上传模型、再上传参考音频与配置声优与情感等信息。
您可以在可视化网页中可以对音频进行裁剪;此处上传对音频格式没有要求,模型管理器会自动转换参考音频为wav音频格式。参考文本语言需要在指定选项中进行选择;定义情感可以自由输入文本或选择选项。
💡 请注意在2025-03-22版本的整合包中,如果您需要在同一模型下设置多个声优与其参考音频,请尽可能在不退出或不刷新网页的情况下完成添加参考音频操作;否则下次您再运行模型管理器时,需要重新上传模型或者输入这个已存在的模型名来指向这个模型。
之后通过语音合成的webUI界面验证能成功配音后,即可在话树内使用。
方式二:手动目录文件管理,更适用于配置大量参考音频或补充新语气的参考音频。
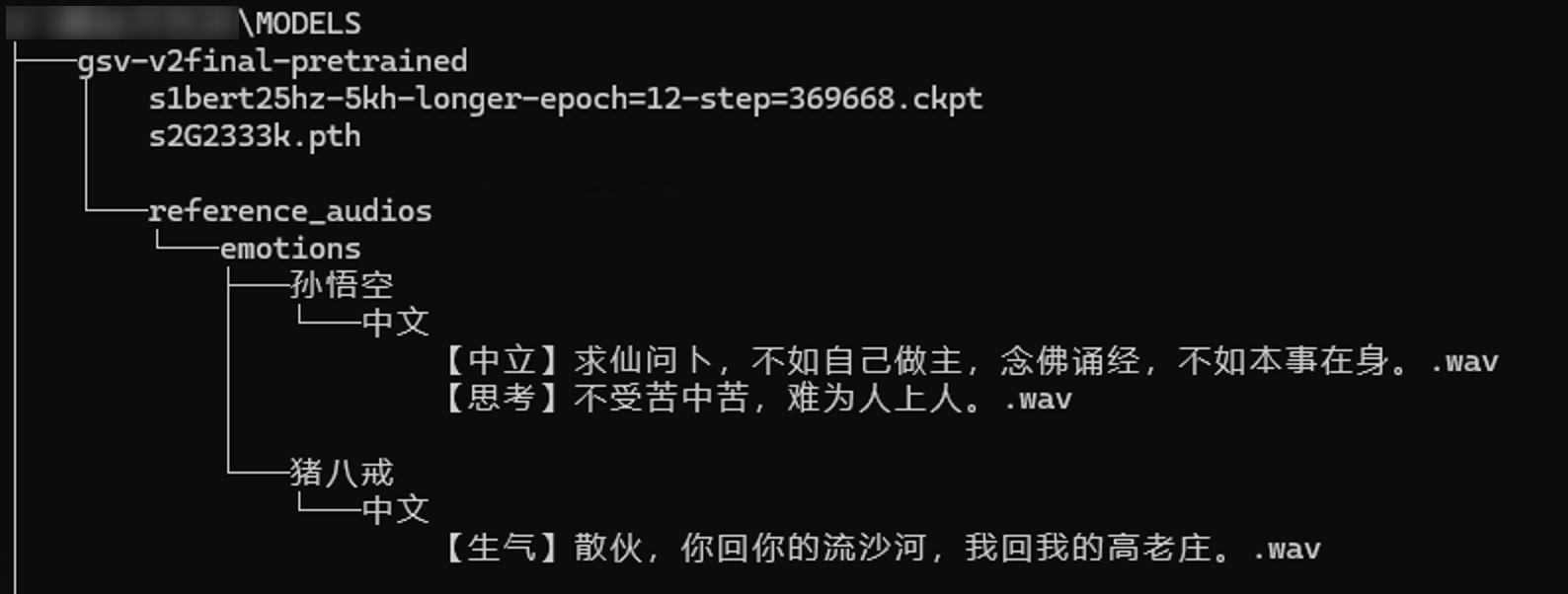
您需要准备好ckpt模型文件与pth模型文件,以及若干播放长度在10秒以内的wav格式的语气音频。
之后请将您的配音模型文件和参考音频等整理文件夹成如图所示的树形结构,放置于整合包的/models文件夹下,通过webUI界面验证能成功配音后,即可在话树内使用。

 text
text【中立】求仙问卜,不如自己做主,念佛诵经,不如本事在身。.wav